OTP 22 亮点
OTP 22 刚刚发布。这是一个漫长的过程,在最终版本发布之前经历了三个候选版本。我们今年决定尝试让主要版本多测试一个月,我认为额外的测试时间是值得的。我们收到了社区关于大小错误的许多错误报告,这些错误我们的内部测试没有发现。
这篇博文将描述 OTP 22 和 OTP 21 维护补丁中发布的一些亮点。
您可以在此处下载描述更改的自述文件:OTP 22 自述文件。或者,像往常一样,查看您感兴趣的应用程序的发布说明。例如这里:OTP 22 Erts 发布说明。
编译器 #
在 OTP 22 中,我们完全重新实现了 Erlang 编译器的较低层。在此更改之前,Erlang 编译器由多个 IR(中间表示)组成。
Erlang AST -> Core Erlang -> Kernel Erlang -> Beam Asm
在编译 Erlang 模块时,代码在这些不同的 IR 之间进行优化和转换。在 OTP 22 中,我们几乎删除了 Kernel Erlang IR,并添加了一个名为 Beam SSA 的新 IR。有一系列博客文章更详细地描述了这一变化,供那些感兴趣的人参考。
通过此更改,编译管道现在如下所示
Erlang AST -> Core Erlang -> Kernel Erlang -> Beam SSA -> Beam Asm
随着 SSA 的重写,引入了许多新的优化。其中之一是对 位语法的加强。在更改之前,您必须非常小心地编写二进制匹配,以便二进制匹配上下文优化能够正常工作。在某些情况下,也根本无法触发优化。Erlang/OTP 中产生重大影响的一个地方是 string:lexemes/1 和其他字符串函数使用的内部 string:bin_search_inv_1 函数。我们可以在下面的基准测试图中看到变化(其中越高越好,绿松石色线在 OTP 22 分支中)
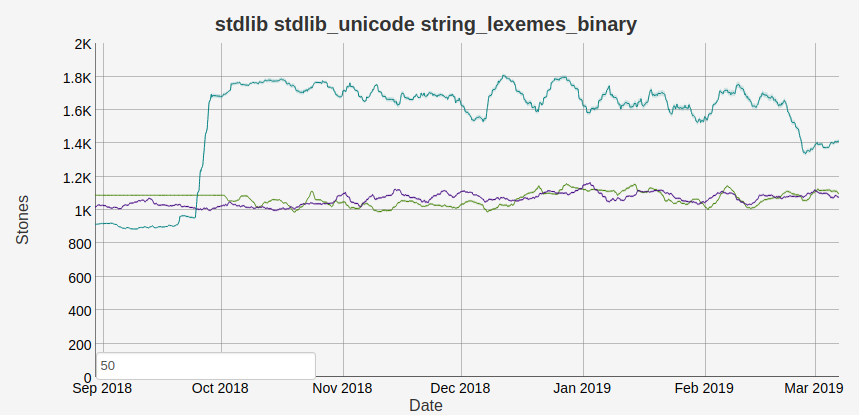
您可以在 PR1958 和 淘汰旧的性能陷阱中阅读有关此优化的更多信息。
另一个很棒的优化是 PR2100,它使编译器类型优化传递可以在同一模块内的函数之间工作。例如,在下面的代码中
-record(myrecord, {value}).
h(#myrecord{value=Val}) ->
#myrecord{value=Val+1}.
i(A) ->
#myrecord{value=V} = h(#myrecord{value=A}),
V.
新的编译器能够检测传递给 h/1 的参数的类型以及 h/1 的返回值,因此它可以完全消除记录检查。查看 h/1 函数的 BEAM 代码(由 erlc -S 生成),我们得到
OTP 21
{test,is_tagged_tuple,{f,9},[{x,0},2,{atom,myrecord}]}.
{get_tuple_element,{x,0},0,{x,1}}.
{get_tuple_element,{x,0},1,{x,2}}.
{gc_bif,'+',{f,0},3,[{x,2},{integer,1}],{x,0}}.
{test_heap,3,1}.
OTP 22
{get_tuple_element,{x,0},1,{x,0}}.
{gc_bif,'+',{f,0},1,[{x,0},{integer,1}],{x,0}}.
{test_heap,3,1}.
is_tagged_tuple 指令已被完全消除,并且作为额外的好处,还删除了一个 get_tuple_element。
但是,这只是开始,我们已经在研究为 OTP 23 进行更好的优化,并以 SSA 重写为基础。
套接字 #
OTP 22 附带了一个新的实验性 套接字 API。此 API 背后的想法是拥有一个稳定的中间 API,用户可以使用它来创建不属于更高级别 gen API 的功能。我们还将使用此 API 在 OTP 23 中重新实现更高级别的 gen API。
新套接字 API 的另一个方面是,它可用于大大减少使用端口固有的开销。我写了名为 gen_tcp2 的 微基准测试,以了解差异可能会是什么。
Erlang/OTP 22 [erts-10.4] [source] [64-bit]
Eshell V10.4 (abort with ^G)
1> gen_tcp2:run().
client server
gen_tcp: 12.4 ns/byte 12.4 ns/byte
gen_tcp2: 7.3 ns/byte 7.3 ns/byte
ratio: 58.9 % 58.9%
ok
结果似乎很有希望。gen_tcp 的套接字实现使用大约 40% 更少的 CPU 来发送相同数量的数据包。当然,gen_tcp 比 gen_tcp2 做的事情多得多(处理大量缓冲区、错误情况和 IPv6 等),因此这绝不是一个公平的比较。但是,如果应用程序可以不用 gen_tcp 附带的所有保证,那么使用套接字对于性能可能会非常好。
ordered_sets 中的写入并发 #
由乌普萨拉大学的 Kjell Winblad 贡献的 PR1952 使得可以并行更新类型为 ordered_set 的 ets 表。这与 Kjell Winblad 和 Sverker Eriksson 的其他改进相结合(PR1997 和 PR2190)大大提高了许多应用程序基础的此类 ets 表的可伸缩性,例如,pg2 和默认 ssl 会话缓存。
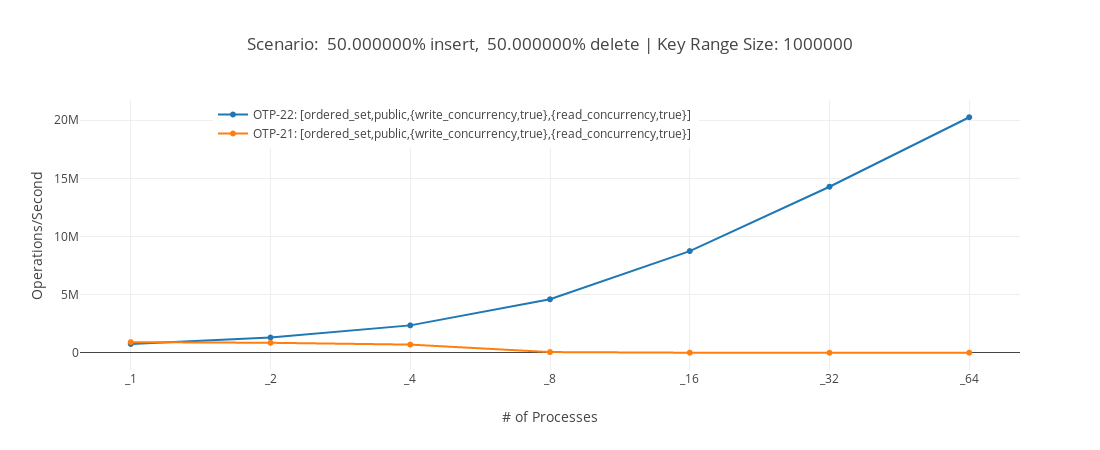
在上面的基准测试中,我们可以看到,在 ordered_set 表上,在 64 核计算机上每秒可能的操作次数在 OTP 21 和 OTP 22 之间显着增加。您可以在 此处查看基准测试的描述和更多基准测试的结果。
用于在 ordered_set 中启用 write_concurrency 的数据结构称为竞争自适应搜索树。简而言之,数据结构保留一个影子树,该树表示读取或写入树中某个术语所需的锁。当多个写入器之间发生冲突时,将更新影子树,以便为树的特定分支使用更细粒度的锁。您可以在 并发有序集合的竞争自适应方法(PDF)中阅读有关该算法的详细信息。
TLS 改进 #
在 OTP 21.3 中,发布了 ssl 应用程序中许多优化的顶点。对于某些用例,使用 TLS 的开销已大大降低。例如,在此 TLS 分布基准测试中
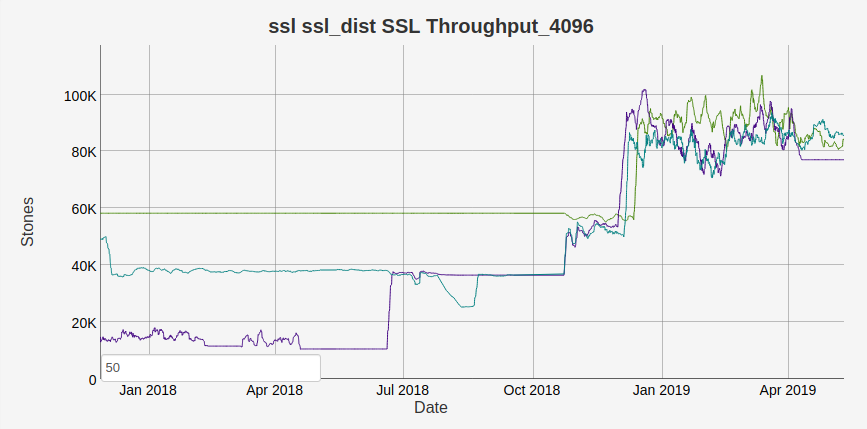
Erlang 通过 TLS 分布能够发送的每秒字节数已从 17K 增加到大约 80K,因此数据量是之前的 4 倍多。上面的吞吐量增益主要是由于更好地批量处理分发消息,这使得 ssl 不必为每个发送的消息添加大量填充。因此,它不会直接转换为使用 ssl,但仍然是一个非常好的性能改进。
在 OTP 22 中,ssl 的日志记录工具得到了极大的改进,现在对 TLSv1.3 有基本的服务器支持。为了使用 TLSv1.3,您需要安装支持 TLSv1.3 的 OpenSSL 版本(例如 1.1.1b),使用该 OpenSSL 版本编译 Erlang/OTP,并生成正确的证书。然后我们可以像这样启动 TLSv1.3 服务器
LOpts = [{certfile, "tls_server_cert.pem"},
{keyfile, "tls_server_key.pem"},
{versions, ['tlsv1.3']},
{log_level, debug}
],
{ok, LSock} = ssl:listen(8443, LOpts),
{ok, CSock} = ssl:transport_accept(LSock),
{ok, S} = ssl:handshake(CSock).
并使用 OpenSSL 客户端进行连接
openssl s_client -debug -connect localhost:8443 \
-CAfile tls_client_cacerts.pem \
-tls1_3 -groups P-256:X25519
这将产生大量日志,但在其中某个位置,我们可以在 Erlang 中看到
<<< TLS 1.3 Handshake, ClientHello
在 OpenSSL 中看到
New, TLSv1.3, Cipher is TLS_AES_256_GCM_SHA384
这意味着我们已成功创建了新的 TLSv1.3 连接。如果您想复制我所做的事情,可以按照这些说明。
并非所有 TLSv1.3 的功能都已实现,您可以在 ssl 应用程序的 标准合规性文档中查看缺少哪些 RFC 部分。
分段分发消息 #
为了解决通过 Erlang 分发发送非常大的消息引起的队头阻塞问题,我们在 OTP 22 中添加了 分发消息的分段。这意味着现在大型消息将被拆分为更小的片段,从而允许发送较小的消息,而不会被长时间阻塞。
如果我们运行以下代码,该代码每 100 毫秒进行一次小型 rpc 调用,并同时发送许多 1/2 GB 的术语。
1> spawn(fun() ->
(fun F(Max) ->
{T, _} = timer:tc(fun() ->
rpc:call(RemoteNode, erlang, length, [[]])
end),
NewMax = lists:max([Max, T]),
[io:format("Max: ~p~n",[NewMax]) || NewMax > Max],
timer:sleep(100),
F(NewMax)
end)(0)
end).
2> D = lists:duplicate(100000000,100000000),
[{kjell, RemoteNode} ! D || _ <- lists:seq(1,100)],
ok.
使用我们的两台测试机器,我在 OTP 22 上的最大延迟约为 0.4 秒,而在 OTP 21 上的最大延迟约为 50 秒。因此,在我们测试站点的网络中,最大延迟减少了约 99%,这是一个不错的改进。
计数器/原子和 persistent_terms #
在 OTP 21.2 中添加了三个新模块,counters、atomics 和 persistent_term。这些模块允许用户访问运行时的底层原语,从而实现一些惊人的性能改进。
例如,最近重新编写了 cover 工具,以使用 counters 和 persistent_term。以前,它使用一堆 ets 表来保存代码执行时的计数器,但现在它使用 counters,运行 cover 的开销最多减少了 80%。
persistent_term 增加了对 mochiglobal 和 类似工具的运行时支持。它可以非常高效地全局访问数据,但代价是使更新非常昂贵。在 Erlang/OTP 中,到目前为止,我们使用它来优化 logger 后端,但用例很多。
atomics 的一个有趣(且可能有用)的用例是创建一个共享可变位向量。因此,现在我们可以生成 100 个进程并互相玩翻转位
BV = bit_vector:new(80),
[spawn(fun F() ->
bit_vector:flip(BV, rand:uniform(80)-1),
F()
end) || _ <- lists:seq(1,100)],
timer:sleep(1000),
bit_vector:print(BV).
文档变更 #
在 OTP 21.3 中,所有函数和模块的 引入版本都已添加到文档中。

Sverker 使用了一些 git 魔术来确定何时添加了函数和模块,并自动更新了所有参考手册。因此,现在应该更容易查看何时引入了某些功能。了解何时添加了函数的选项仍然存在问题,但我们也正在努力做得更好。
在 OTP 22 中,一个名为 内部文档 的新文档顶部部分已添加到 erts 和 compiler 应用程序中。这些部分包含以前只能在 github 上找到的内部文档,以便更容易访问。
更多内存优化 #
每个主要的 OTP 版本发布都少不了对内存分配器的一系列改进,OTP 22 也不例外。其中最有可能影响您的应用程序的是 PR2046 和 PR1854。 这两个优化都应该允许系统在高内存情况下更好地利用内存载体,从而使您的系统能够处理更大的负载。