查看源代码 BeamAsm,Erlang JIT
BeamAsm 提供了在 x86-64 和 aarch64 上将 Erlang BEAM 指令加载时转换为本机代码的功能。这使得加载器能够消除任何指令分派的开销,并根据其参数类型专门化每个指令。
BeamAsm 几乎不做跨指令优化,并且 x 和 y 寄存器数组的工作方式与解释 BEAM 指令时相同。这使得 Erlang 运行时系统基本保持不变,除了需要使用已加载 BEAM 指令的地方,例如代码加载、跟踪和其他一些地方。
BeamAsm 使用 asmjit 在运行时生成本机代码。仅使用了 asmjit 的 Assembler API 的一小部分。目前,asmjit 仅支持 x86 32/64 位和 aarch64 汇编器。
加载代码
代码的加载方式与解释器加载代码的方式非常相似。每个 beam 文件都会被解析,然后通过 beam_makeops 中描述的转换进行优化。BeamAsm 中使用的转换比解释器的简单得多,因为解释器的大部分转换只是为了消除指令分派的开销。
然后,使用 jit/$ARCH/instr_*.cpp 文件中的 C++ 函数对每个指令进行编码。例如
void BeamModuleAssembler::emit_is_nonempty_list(const ArgVal &Fail, const ArgVal &Src) {
a.test(getArgRef(Src), imm(_TAG_PRIMARY_MASK - TAG_PRIMARY_LIST));
a.jne(labels[Fail.getLabel()]);
}asmjit 提供了一个相当直接的从 C++ 函数调用到 x86 汇编指令的映射。上面的指令测试 Src 寄存器中的值是否为非空列表,如果不是,则跳转到 fail 标签。
作为比较,解释器有 8 种此实现的组合和专门化,以最大限度地减少常见模式的指令分派开销。
Erlang 编译器完成的原始寄存器分配用于管理值的活跃性,并且静态分配物理寄存器以保持必要的进程状态。目前,这是 x86-64 上的静态寄存器分配
rbx: ErtsSchedulerRegisters struct (contains x/float registers and some metadata)
rbp: Current frame pointer when `perf` support is enabled, otherwise this
is an optional save slot for the Erlang stack pointer when executing C
code.
r12: Active code index
r13: Current running process
r14: Remaining reductions
r15: Erlang heap pointer请注意,所有这些都是 System V 和 Windows ABI 下的被调用者保存寄存器,这意味着 BeamAsm 在进行 C 函数调用时永远不必溢出任何这些寄存器。
调用者保存寄存器在指令内用作暂存寄存器,但通常不在它们之间传递信息。对于一些频繁的指令序列,例如元组匹配,会进行跨指令优化,以避免在每个 get_tuple_element 指令中获取元组的基地址。
减少代码大小和加载时间
解释器的优势之一是它为加载的代码使用了相对较少的内存。这是因为每个加载指令的实现都是共享的,只有指令的参数会发生变化。尽可能少地使用内存有很多优点:使用更少的内存,减少加载时间,更高的缓存命中率。
在 BeamAsm 中,我们需要实现类似的功能,因为模块的加载时间几乎与其使用的内存量成线性比例。早期的 BeamAsm 原型使用的代码内存量约为解释器的两倍,而当前版本使用的内存量约为解释器的 10%。这是如何实现的?
在 BeamAsm 中,我们大量使用共享代码片段,以尝试尽可能多地将代码作为全局共享片段发出,而不是不必要地复制代码。例如,return 指令看起来像这样
Label yield = a.newLabel();
/* Decrement reduction counter */
a.dec(FCALLS);
/* If FCALLS < 0, jump to the yield-on-return fragment */
a.jl(resolve_fragment(ga->get_dispatch_return()));
a.ret();上面的代码并不完全是发出的代码,但足够接近。需要注意的是,用于执行上下文切换的代码永远不会发出。相反,我们跳转到所有 return 指令共享的全局片段。这大大减少了每个模块必须发出的代码量。
运行 Erlang 代码
运行 BeamAsm 代码与运行解释器非常相似,只是执行的是本机代码而不是解释代码。
我们必须调整 Erlang 堆栈的工作方式,以便在其上执行本机指令。当解释器使用一个堆栈槽作为当前帧的返回地址(在未使用时将其设置为 [])时,本机代码只是为其保留足够的空间,因为 x86 call 和 ret 指令在执行时会增加堆栈指针。
这仅影响当前堆栈帧,并且除了以下两个注意事项外,在功能上是相同的
当返回地址被保留时,不能抛出异常。
很难知道在异常发生后堆栈将最终到达哪里;如果我们在当前堆栈帧中崩溃,则返回地址将不会在堆栈上,但如果我们在我们调用的函数中崩溃,则会在堆栈上。区分这些情况非常复杂,因此我们决定要求在抛出异常时必须使用返回地址。
emit_handle_error会为您处理此问题,并且默认情况下,已调用(而不是跳转到)的共享片段会满足此要求。垃圾回收需要考虑返回地址。
如果我们即将创建一个 term,我们必须确保有足够的空间容纳这个 term 和一个潜在的返回地址,否则下一个
call将会覆盖该 term。这在emit_gc_test中处理,您通常不需要考虑它。
除了上述内容外,我们还要确保堆栈上始终至少有 S_REDZONE 个空闲字,这样即使我们缺少堆栈帧,也可以调用共享片段或跟踪处理程序。这仅仅是一个保留,不会影响堆栈的工作方式,并且为了进行垃圾回收,存储在那里的所有值必须是有效的 Erlang term。
帧指针
为了帮助调试器和采样分析器,我们支持使用本机帧指针运行 Erlang 代码。在撰写本文时,这仅与 perf 支持 (+JPperf true) 一起启用,以节省堆栈空间,但我们可能会在将来添加一个标志来显式启用它。
启用后,连续指针 (CP) 同时具有返回地址和指向前一个 CP 的帧指针。CP 必须始终形成有效的链,并且在检查堆栈时拥有“一半”CP 是非法的。
帧指针在进入 Erlang 函数时被压入,并在离开时被弹出,包括在尾部调用中,因为被调用者会在进入时立即压入帧指针。这会产生轻微的开销,但可以避免我们为每个函数设置多个入口点的麻烦,具体取决于它是尾部调用还是主体调用,一旦断点进入画面,这会变得非常棘手。
运行 C 代码
由于 Erlang 堆栈可能非常小,因此当我们需要执行 C 代码(它可能需要更大的堆栈)时,我们必须切换到不同的堆栈。这通过 emit_enter_runtime 和 emit_leave_runtime 完成,例如
mov_arg(ARG4, NumFree);
/* Move to the C stack and swap out our current reductions, stack-, and
* heap pointer to the process structure. */
emit_enter_runtime<Update::eReductions | Update::eStack | Update::eHeap>();
a.mov(ARG1, c_p);
load_x_reg_array(ARG2);
make_move_patch(ARG3, lambdas[Fun.getValue()].patches);
/* Call `new_fun`, asserting that we're on the C stack. */
runtime_call<4>(new_fun);
/* Move back to the C stack, and read the updated values from the process
* structure */
emit_leave_runtime<Update::eReductions | Update::eStack | Update::eHeap>();
a.mov(getXRef(0), RET);Update 常量的所有组合都是合法的,但传递给 emit_leave_runtime 的常量必须与传递给 emit_enter_runtime 的常量相同。
跟踪和 NIF 加载
为了使跟踪和 NIF 加载工作,需要有一种方法来拦截任何函数调用。在解释器中,这是通过重写加载的 BEAM 代码来完成的,但在 BeamAsm 中,这更复杂,因为我们希望有一种快速紧凑的方法来执行此操作。这通过在每个函数的开头发出以下代码来解决(以下是 x86 变体)
0x0: short jmp 6 (address 0x8)
0x2: nop
0x3: relative near call to shared breakpoint fragment
0x8: actual code for function当代码开始执行时,它将简单地看到 short jmp 6 指令,该指令会跳过序言并直接开始执行代码。
当我们想要启用某个断点时,我们将 jmp 目标设置为 1,这意味着它将落在对共享断点片段的调用上。此片段会检查存储在此函数的 ErtsCodeInfo 中的当前 breakpoint_flag,然后相应地调用 erts_call_nif_early 和 erts_generic_breakpoint。
请注意,分支和 breakpoint_flag 的更新不需要是原子的:如果进程只看到其中一个被更新,则没有问题,因为设置断点/加载 NIF 的代码不依赖于 trampoline,直到线程取得进展。
AArch64 的解决方案类似。
更新代码
由于许多环境强制执行 W^X,因此并非总是可以直接写入代码页。因此,我们将代码映射两次:一次映射到可执行页面,一次映射到可写页面。由于它们由相同的内存支持,因此对可写页面的写入会神奇地出现在可执行页面中。
可以使用 erts_writable_code_ptr 函数来获取给定模块实例的可写指针,前提是该模块实例已首先被解封
for (i = 0; i < n; i++) {
const ErtsCodeInfo* ci_exec;
ErtsCodeInfo* ci_rw;
void *w_ptr;
erts_unseal_module(&modp->curr);
ci_exec = code_hdr->functions[i];
w_ptr = erts_writable_code_ptr(&modp->curr, ci_exec);
ci_rw = (ErtsCodeInfo*)w_ptr;
uninstall_breakpoint(ci_rw, ci_exec);
consolidate_bp_data(modp, ci_rw, 1);
ASSERT(ci_rw->gen_bp == NULL);
erts_seal_module(&modp->curr);
}如果没有模块实例,则无法可靠地计算出代码页的可写地址,我们依靠地址空间布局随机化 (ASLR) 来使其难以猜测。在某些平台上,安全性的进一步增强是通过保护可写区域免受写入,直到模块已被 erts_unseal_module 解封。
导出跟踪
与解释器不同,我们不在导出条目内执行代码,因为在面对 W^X 时这样做非常烦人。启用跟踪后,我们改为指向一个片段,该片段会查看当前导出条目并决定该怎么做。
此片段在所有导出条目之间共享,并且假定要操作的导出条目位于某个寄存器中(在撰写本文时为 RET)。这意味着所有远程调用必须将导出条目放入所述寄存器中,即使我们事先不知道该调用是远程的,例如在调用 fun 时。
这在汇编器中很容易做到,并且 emit_setup_dispatchable_call 辅助函数可以很好地处理它,但是当从 C 代码中陷出时,我们无法设置寄存器。当从 C 代码陷阱到导出条目时,必须将 c_p->current 设置为相关导出条目内的 ErtsCodeMFA,然后将 c_p->i 设置为 beam_bif_export_trap。
BIF_TRAP 宏会为您处理此问题,因此您通常不需要考虑它。
每个文件的描述
BeamAsm 实现位于 $ERL_TOP/erts/emulator/beam/jit 文件夹中。文件包括
asm_load.c- 用于加载代码的 BeamAsm 特定函数
beam_asm.h- 描述 C -> C++ API 的头文件
beam_jit_metadata.cpp- BeamAsm 的
gdb和 Linuxperf支持
- BeamAsm 的
load.h- 加载代码的 BeamAsm 特定头文件
$ARCH/beam_asm.hpp- 描述 BeamAsm 使用的结构体和类的头文件。
$ARCH/beam_asm.cpp- BeamAsm 初始化代码
- C -> C++ 接口函数。
$ARCH/generators.tab,$ARCH/predicates.tab,$ARCH/ops.tab- 指令的 BeamAsm 特定转换。有关详细信息,请参阅 beam_makeops。
$ARCH/beam_asm_module.cpp- BeamAsm 模块代码生成器逻辑的代码
$ARCH/beam_asm_global.cpp- 多个指令使用的全局代码片段,例如错误处理代码。
$ARCH/instr_*.cpp- 按区域分组的文件中各个指令的实现
$ARCH/process_main.cpp- 主进程循环的实现
Linux perf 支持
JIT 可以向 Linux 分析器 perf 提供符号,从而可以使用它来分析 Erlang 代码。根据使用的模式,perf 将提供类似于 eprof 或 fprof 的功能,但开销低得多(且可配置)。
您可以通过以下方式在 BeamAsm 上运行 perf
# Start Erlang under perf
perf record -- erl +JPperf true
# Record a running instance started with `+JPperf true` for 10s
perf record --pid $BEAM_PID -- sleep 10
# Record a running instance started with `+JPperf true` until interrupted
perf record --pid $BEAM_PID然后像通常使用 perf 一样使用 perf report 查看结果。
当传递 +JPperf true 选项时,会启用帧指针,因此您可以使用 perf record --call-graph=fp 来获取更多上下文,使结果类似于 fprof 的结果。这将为您提供纯 Erlang 代码的准确调用图,但在极少数情况下,它无法跟踪从 Erlang 到 C 代码以及从 C 代码返回的转换。在这些情况下,perf record --call-graph=lbr 可能会更好,但它在一般跟踪方面表现较差。
例如,您可以运行 perf 来分析 dialyzer 构建 PLT,如下所示
ERL_FLAGS="+JPperf true +S 1" perf record --call-graph=fp \
dialyzer --build_plt -Wunknown --apps compiler crypto erts kernel stdlib \
syntax_tools asn1 edoc et ftp inets mnesia observer public_key \
sasl runtime_tools snmp ssl tftp wx xmerl tools上面的代码使用 +S 1 运行,以使 perf 输出更容易理解。如果然后运行 perf report -f --no-children,您可能会得到类似的结果
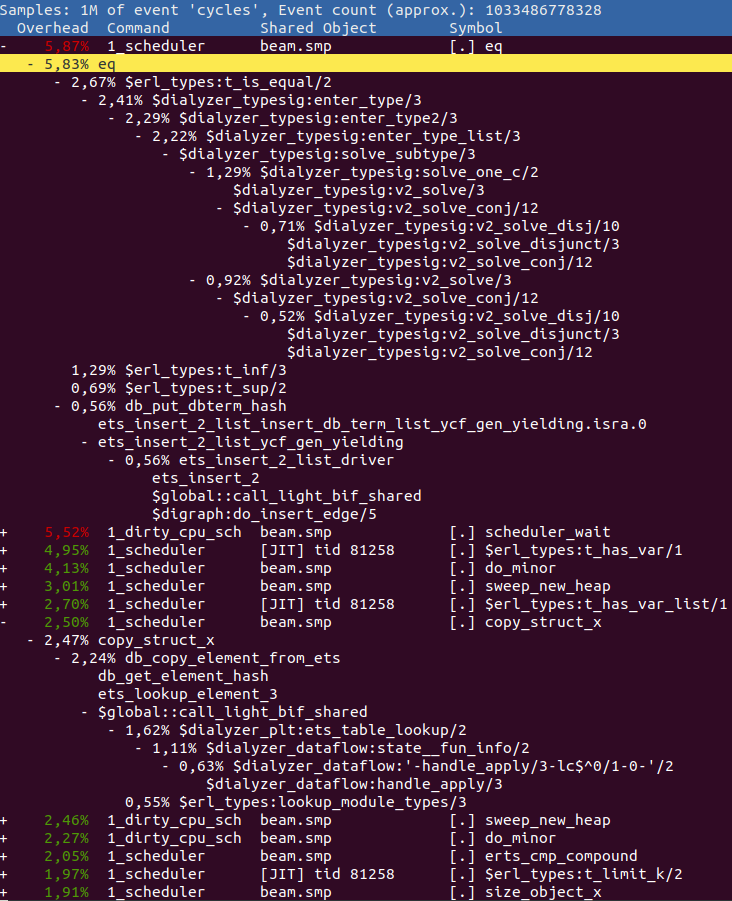
报告中的任何 Erlang 函数都以 $ 为前缀,所有 C 函数都有其正常名称。任何具有前缀 $global:: 的 Erlang 函数都指的是一个全局共享片段。
因此,在上面,我们可以看到我们花费最多时间在执行 eq,即比较两个项。通过展开它并查看其父项,我们可以看到是函数 erl_types:t_is_equal/2 对此值贡献最大。查看源代码,看看是否可以弄清楚为什么在这里花费了这么多时间。
在 eq 之后,我们看到函数 erl_types:t_has_var/1,我们几乎将整个执行时间的 5% 花费在其中。再往下,您可以看到 copy_struct_x,它是用于复制项的函数。如果展开它以查看父项,我们发现主要是 ets:lookup_element/3 通过 Erlang 函数 dialyzer_plt:ets_table_lookup/2 对此时间做出了贡献。
火焰图
您还可以从 perf 输出创建火焰图。火焰图基本上只是另一种查看与 perf report 输出相同数据的方式,但可以更轻松地与他人共享和操作,以提供为您的需求量身定制的图。例如,如果我们使用所有调度程序运行 dialyzer
## Run dialyzer with multiple schedulers
ERL_FLAGS="+JPperf true" perf record --call-graph=fp \
dialyzer --build_plt -Wunknown --apps compiler crypto erts kernel stdlib \
syntax_tools asn1 edoc et ftp inets mnesia observer public_key \
sasl runtime_tools snmp ssl tftp wx xmerl tools --statistics然后使用 Brendan Gregg 的 CPU 火焰图 网页上的脚本,如下所示
## Collect the results
perf script > out.perf
## run stackcollapse
stackcollapse-perf.pl out.perf > out.folded
## Create the svg
flamegraph.pl out.folded > out.svg我们会得到一个类似于这样的图

您可以在此处查看更大的版本。它包含相同的信息,但它更容易与他人共享,因为它不需要可执行文件中的符号。
使用相同的数据,我们还可以生成一个图,其中调度程序配置文件数据已使用 sed 合并
## Strip [0-9]+_ and/or _[0-9]+ from all scheduler names
## scheduler names changed in OTP26, hence two expressions
sed -e 's/^[0-9]\+_//' -e 's/^erts_\([^_]\+\)_[0-9]\+/erts_\1/' out.folded > out.folded_sched
## Create the svg
flamegraph.pl out.folded_sched > out_sched.svg
您可以在此处查看更大的版本。您可以执行许多不同的转换来使图形显示您想要的内容。
注释 perf 函数
如果要使用 perf annotate 功能(以及扩展的 perf report gui 中的注释功能),则需要在调用 perf record 时使用单调时钟,即 perf record -k mono。因此,对于 dialyzer 运行,您将执行此操作
ERL_FLAGS="+JPperf true +S 1" perf record -k mono --call-graph=fp \
dialyzer --build_plt -Wunknown --apps compiler crypto erts kernel stdlib \
syntax_tools asn1 edoc et ftp inets mnesia observer public_key \
sasl runtime_tools snmp ssl tftp wx xmerl tools要使用此记录生成的 perf.data,您需要首先像这样调用 perf inject --jit
perf inject --jit -i perf.data -o perf.jitted.data然后您可以像这样查看注释的函数
perf annotate -M intel -i perf.jitted.data erl_types:t_has_var/1或者通过在 perf report ui 中按 a。然后你得到这样的东西
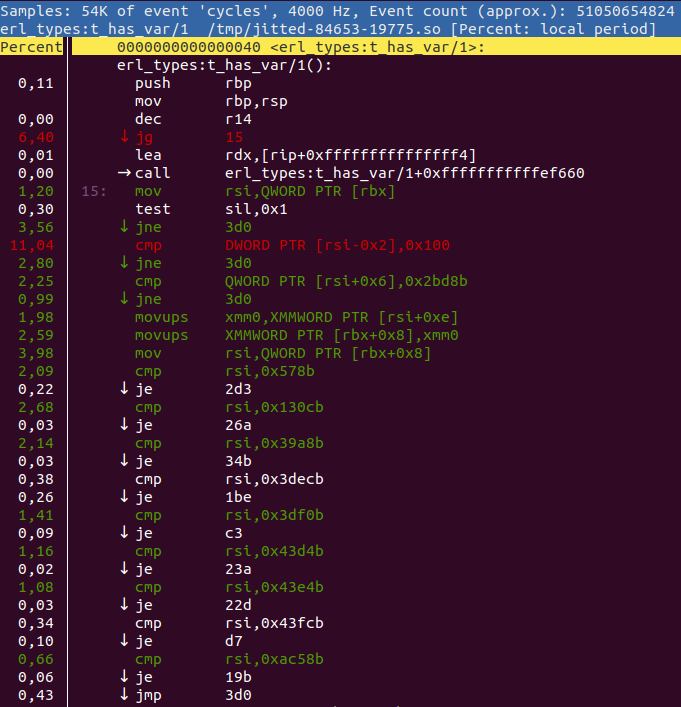
如果可能,perf annotate 会将列表与原始源代码交错。您可以使用 +{source,Filename} 或 +absolute_paths 编译器选项来告诉 perf 在哪里找到源代码。
警告:调用
perf inject --jit将在/tmp/和~/.debug/tmp/中创建许多文件。因此,请确保不时清理这些目录,否则您可能会耗尽 inode。
在另一台主机上检查 perf 数据
有时,无法或不希望在目标计算机上检查录制内容,这有点棘手,因为 perf report 依赖于所有可用的符号。
要在另一台计算机上检查录制内容,您可以使用 perf archive 命令将所有必需的符号捆绑到一个存档中。这要求录制内容使用 -k mono 标志进行录制,并且已使用 perf inject --jit 处理过
perf inject --jit -i perf.data -o perf.jitted.data
perf archive perf.jitted.data获得存档后,将其与处理后的录制内容一起移动到您希望在上面检查录制内容的主机,并将存档解压缩到 ~/.debug。然后,您可以像往常一样使用 perf report -i perf.jitted.data。
如果您收到类似如下的错误消息
perf: 'archive' is not a perf-command. See 'perf --help'.
那么您的 perf 版本太旧了,您应该使用 此 bash 脚本。
perf 提示和技巧
您可以使用 perf 做很多很酷的事情。以下是我们发现有用的一些选项列表
perf report --no-children不包括调用中所有子项的累积。perf report --call-graph callee在展开函数调用时显示被调用者而不是调用者。perf report给出“failed to process sample”和/或“failed to process type: 68” 这可能意味着您正在运行 perf 的一个错误版本。当在内核版本为 4 的 Ubuntu 18.04 上运行时,我们已经看到过这种情况。如果您更新到 Ubuntu 20.04 或使用内核版本为 5 的 Ubuntu 18.04,则该问题应该会消失。
常见问题解答
我如何知道我正在运行启用 JIT 的 Erlang?
启动时,您将在 shell 中看到一个包含 [jit] 的横幅。您还可以使用 erlang:system_info(emu_flavor) 来检查 flavor,它应该是 jit。
在构建 Erlang/OTP 时,您无法获得 JIT 的两个主要原因。
- 您不是在为 x86 或 ARM 构建 64 位模拟器
- 您没有支持 C++-17 的 C++ 编译器
如果您运行 ./configure --enable-jit,当 configure 发现您的系统无法构建 JIT 时,它将中止。
解释器仍然可用吗?
是的,如果您愿意,您仍然可以构建解释器。实际上,这就是 BeamAsm 尚未工作的平台上使用的内容。您可以通过将 --disable-jit 传递给 configure 来完全禁用 BeamAsm。或者,您可以使用 make FLAVOR=emu 构建解释器,然后使用 erl -emu_flavor emu 运行它。
可以同时使用 JIT 和解释器。
与解释器相比,我应该期望从 BeamAsm 中获得多少加速?
这在很大程度上取决于您的应用程序的功能。从没有差异到快四倍都有可能。
BeamAsm 非常努力地不比解释器慢,但有时可能会发生这种情况。一个这样的情况可能是非常短暂的小脚本。如果您遇到任何发生这种情况的场景,请在 Erlang/OTP 错误跟踪器上打开一个错误报告。
是否可以在其他 CPU 架构上添加对 BeamAsm 的支持?
任何新的架构都需要汇编程序的支持。由于我们为此使用了 asmjit,这意味着我们需要 asmjit 的支持。 BeamAsm 使用相对较少的指令(主要是 mov、jmp、cmp、sub、add),因此不需要对所有指令的完整支持。
另一种方法是不在新架构上使用 asmjit,而是使用其他方法在加载时汇编代码。
是否可以在其他操作系统上添加对 BeamAsm 的支持?
如果操作系统支持将内存映射为可执行文件,那么添加运行 x86-64 或 aarch64 的新操作系统应该不需要进行任何大的更改。如果操作系统使用的 ABI 不受支持,则还必须对调用 C 函数的相关部分进行更改。
作为参考,我们花了大约 2-3 周的时间来实现对 Windows 的支持,以及大约三个月的时间来完成 aarch64 端口。