新的可扩展 ETS ordered_set
在 Erlang/OTP 22 中,使用 write_concurrency 选项的 ordered_set 类型的 ETS 表的可扩展性比早期版本有了显著提高。在某些极端情况下,Erlang/OTP 22 的吞吐量比 Erlang/OTP 21 高出 100 倍以上。这种改进的原因是一种名为争用自适应搜索树(简称 CA 树)的新数据结构。这篇博文将深入探讨 CA 树的工作原理,并向您展示在 OTP 21 和 OTP 22 中比较 ETS ordered_set 表性能的基准测试结果。
亲自尝试! #
这个 escript 让您可以方便地在您自己的机器上,安装 Erlang/OTP 22+ 后,尝试新的 ordered_set 实现。
该 escript 测量 P 个 Erlang 进程将 N 个整数插入到 ordered_set ETS 表所需的时间,其中 P 和 N 是 escript 的参数。只有当 ETS 表选项 ordered_set 和 {write_concurrency, true} 处于活动状态时,才会使用 CA 树。因此,可以很容易地将新数据结构的性能与旧数据结构的性能进行比较(一个由单个读写锁保护的 AVL 树)。在 Erlang/OTP 22 发布之前,write_concurrency 选项对 ordered_set 表没有影响。
当我们在具有两个内核的开发人员笔记本电脑(Intel(R) Core(TM) i7-7500U CPU @ 2.70GHz)上运行 escript 时,会得到以下结果
$ escript insert_disjoint_ranges.erl old 1 10000000
Time: 3.352332 seconds
$ escript insert_disjoint_ranges.erl old 2 10000000
Time: 3.961732 seconds
$ escript insert_disjoint_ranges.erl old 4 10000000
Time: 6.382199 seconds
$ escript insert_disjoint_ranges.erl new 1 10000000
Time: 3.832119 seconds
$ escript insert_disjoint_ranges.erl new 2 10000000
Time: 2.109476 seconds
$ escript insert_disjoint_ranges.erl new 4 10000000
Time: 1.66509 seconds
我们看到,在这个特定的基准测试中,CA 树具有比旧数据结构更好的可扩展性。使用新数据结构和四个进程运行基准测试的速度大约是使用旧数据结构和一个进程运行的两倍(该机器只有两个内核)。在描述 CA 树的工作原理之后,我们将更详细地研究基于新的 CA 树的实现的性能和可扩展性。
争用自适应搜索树简述 #
CA 树与其他并发数据结构的区别在于,CA 树会根据数据结构内部检测到的争用程度动态更改其同步粒度。这样,CA 树可以避免因使用许多不必要的锁而产生的性能和内存开销,而不会在许多操作并行发生时牺牲性能。例如,假设一个场景,其中 CA 树最初由多个线程并行填充,然后仅从单个线程使用。在这种情况下,CA 树将自适应地在填充阶段使用细粒度同步(当细粒度同步减少争用时)。然后,CA 树将更改为在单线程阶段使用粗粒度同步(当粗粒度同步减少锁定和内存开销时)。
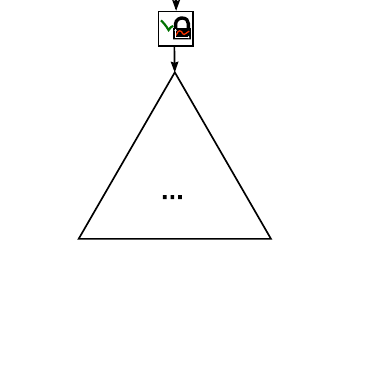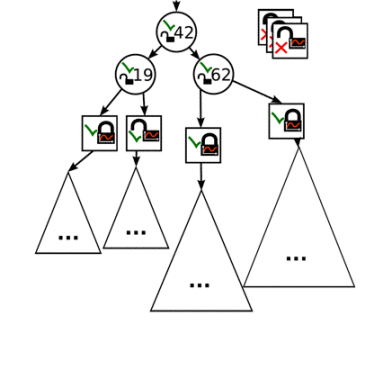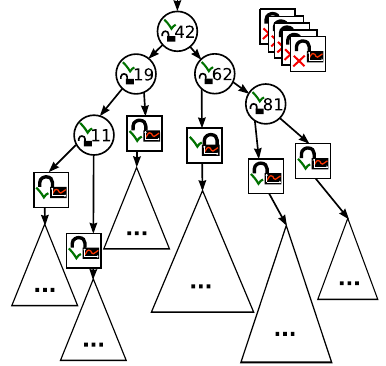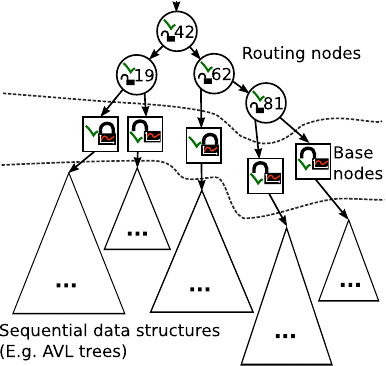
CA 树的结构如下图所示

CA 树中存储的实际项位于底层顺序数据结构中。这些顺序数据结构由中间层基本节点中的锁保护。基本节点锁具有与之关联的计数器。当在基本节点锁中检测到争用时,基本节点锁的计数器会增加;当未检测到此类争用时,该计数器会减少。此基本节点锁计数器的值决定了在基本节点中执行操作后是否应进行拆分或合并。上图顶部的路由节点形成一个二叉搜索树,用于指导对特定项的搜索。路由节点还包含一个锁和一个标志。这些在合并基本节点时使用。本文不会描述拆分和合并如何工作的细节,但有兴趣的读者可以在这篇 CA 树论文 中找到详细描述(预印本 PDF)。现在,我们将通过一个示例来说明 CA 树如何更改其同步粒度
-
最初,CA 树仅由一个具有顺序数据结构的基本节点组成,如下图所示

-
如果并行线程访问 CA 树,则基本节点计数器的值最终可能会达到指示应拆分基本节点的阈值。基本节点拆分会将基本节点中的项划分为两个新的基本节点,并用路由节点替换原始基本节点,其中两个新的基本节点扎根。下图显示了在树的根指向的基本节点拆分后 CA 树的样子

-
只要基本节点锁中有足够的争用或直到达到路由层的最大深度,基本节点拆分的过程将继续进行。下图显示了再次拆分后 CA 树的样子

-
如果例如,CA 树的特定部分比其余部分更频繁地并行访问,则 CA 树的不同部分的同步粒度可能会有所不同。下图显示了又一次拆分后的 CA 树

-
下图显示了第四次拆分后的 CA 树

-
下图显示了第五次拆分后的 CA 树

-
可以合并持有相邻项范围的两个基本节点。在操作看到基本节点计数器的值低于某个阈值后,将触发这种合并。请记住,如果线程在获取基本节点的锁时没有遇到争用,则基本节点的计数器会减少。

-
正如您可能从上面的插图中注意到的那样,拆分和合并导致旧的基本节点和路由节点从树中拼接出来。这些节点占用的内存需要回收,但这不能在它们被拼接出来后立即发生,因为某些线程可能仍在读取它们。Erlang 运行时系统具有一种称为线程进度的机制,ETS CA 树实现使用该机制来安全地回收这些节点。

单击此处可查看示例的动画。
{kind=link}
基准测试 #
新的基于 CA 树的 ETS ordered_set 实现的性能已在基准测试中进行了评估,该基准测试测量了许多场景中的吞吐量(每秒操作数)。该基准测试允许可配置数量的 Erlang 进程对单个 ETS 表执行可配置的操作分布。好奇的读者可以在 ETS 的测试套件中找到该基准测试的源代码。
以下图表显示了在具有两个 Intel(R) Xeon(R) CPU E5-2673 v4 @ 2.30GHz 的机器上(总共 32 个内核,带超线程)此基准测试的结果。所有场景中的平均集合大小约为 500K。有关基准测试机器和配置的更多详细信息,请访问 此页面。








我们看到,当我们添加内核一直到 64 个内核时,基于 CA 树的 ordered_set (OTP-22) 的吞吐量会提高,而旧实现 (OTP-21) 的吞吐量在添加更多进程时通常会变差。旧实现的写入操作是串行化的,因为该数据结构受单个读写锁保护。旧版本在添加更多内核时的速度下降主要是由于当更多内核尝试获取同一锁时通信开销增加,以及竞争内核频繁地使彼此的缓存行失效这一事实造成的。
100% 查找场景的图表(上面图表列表中的最后一个图表)乍一看有点奇怪。为什么在这种情况下,CA 树的扩展性比旧实现好得多?如果不了解 ordered_set 表类型的实现细节,几乎不可能猜出答案。首先,CA 树对它的基本节点锁使用了与旧实现用来保护整个表的相同的读写锁实现。因此,差异不是由于任何锁差异造成的。默认的 ordered_set 实现(当 write_concurrency 关闭时处于活动状态的实现)具有一个优化,该优化主要改进了单个进程迭代表项的使用场景,例如,使用一系列对 ets:next/2 函数的调用。此优化为每个表保留一个静态堆栈。某些操作使用此堆栈来减少需要遍历的树节点数量。例如,如果堆栈的顶部包含与传递给操作的键相同的键,则 ets:next/2 操作不需要重新创建堆栈(请参见 此处)。由于每个表只有一个静态堆栈,并且可能有许多读取器(由于读写锁),因此静态堆栈必须由当前正在使用它的线程保留。不幸的是,静态堆栈处理是诸如上面 100% 查找之类的场景中的可扩展性瓶颈。CA 树实现没有这种类型的优化,因此它不会受到此可扩展性瓶颈的影响。但是,这也意味着当主要顺序访问表时,旧的实现可能会比新的实现表现更好。当旧的实现(仍然可以通过将 write_concurrency 选项设置为 false 来使用)表现更好的一种情况是,在 10% insert、10% delete、40% lookup 和 40% nextseq1000(一系列 1000 个 ets:next/2 调用)的场景的单进程情况下(上面图表列表中的倒数第二个图表)。
因此,我们可以得出结论,如果从多个进程并行访问 ordered_set 表,则为该表启用 write_concurrency 可能是一个好主意。但是,如果您主要按顺序访问该表,则关闭 write_concurrency 可能会更好。
关于分散式计数器的说明 #
CA 树实现并不是在 Erlang/OTP 22 中引入的唯一优化,它影响了启用 write_concurrency 的 ordered_set 的可扩展性。Erlang/OTP 22 中还引入了一个优化,该优化将启用 write_concurrency 的 ordered_set 表中的计数器分散化(请参见 此处)。在 Erlang/OTP 23 中引入了一个在所有表类型中启用相同优化的选项(请参见 此处)。您可以在此处找到比较具有和不具有分散式计数器的表的可扩展性的基准测试结果。
进一步阅读 #
以下论文比本博客文章更详细地描述了 CA 树以及一些优化(其中一些尚未应用于 ETS CA 树)。该论文还包括与相关数据结构的实验比较。
- 一种用于并发有序集合的争用自适应方法 (预印本)。《并行与分布式计算杂志》,2018。Konstantinos Sagonas 和 Kjell Winblad
还有一种 CA 树的无锁变体,在以下论文中进行了描述。无锁 CA 树在其基本节点中使用不可变的数据结构,以大幅减少范围查询的时间,以及类似操作可能与其他操作冲突的情况。
- 无锁争用自适应搜索树 (预印本)。在第 30 届并行算法与架构研讨会 (SPAA 2018) 会议记录中。Kjell Winblad、Konstantinos Sagonas 和 Bengt Jonsson。
以下论文讨论和评估了用于 ETS 的原型 CA 树实现,是第一篇与 CA 树相关的论文。
- 使用自适应的 ETS 更具可扩展性的有序集合 (预印本)。在第十三届 ACM SIGPLAN Erlang 研讨会 (2014) 上。Konstantinos Sagonas 和 Kjell Winblad
如果您对具体的实现细节感兴趣,可以直接查看 ETS CA 树源代码。最后,如果您想获取更多相关工作的链接或想了解更多关于适应争用的并发数据结构的动机,查看作者的博士论文也可能很有意思。
结论 #
Erlang/OTP 22 版本引入了一个新的 ETS ordered_set 实现,当 write_concurrency 选项打开时,该实现处于活动状态。这种数据结构(一种争用自适应搜索树)在许多不同的场景中比旧的数据结构具有更强的可扩展性,并且其设计在各种受益于不同同步粒度的场景中都具有出色的性能。